# 计算机发展历程
| 发展阶段 | 时间 | 逻辑元件 | 速度 (次 / 秒) | 内存 | 外存 | |
|---|---|---|---|---|---|---|
| 第一代 | 1946-1957 | 电子管 | 几千 - 几万 | 汞延迟线、磁鼓 | 穿孔卡片、纸袋 | |
| 第二代 | 1958-1964 | 晶体管 | 几万 - 几十万 | 磁芯存储器 | 磁带 | |
| 第三代 | 1964-1971 | 中小规模集成 | 几十万 - 几百万 | 半导体存储器 | 磁带、磁盘 | 电路 |
| 第四代 | 1972 - 现在 | 大规模、超大规模集成电路 | 上千万 - 万亿 | 半导体存储器 | 磁盘、磁带、光盘、半导体存储器 |
# 世界上第一台计算机
ENIAC:Electronic Numerical Integrator And Computer
# IAS
- 冯诺依曼 / 图灵
- 开始与 1946 年,但 1952 年也未能完成
- 存储程序概念
- 主存储器存储程序和数据
- 操作二进制数据的 ALU
- 控制单元解释指令从内存和执行它们
- 由控制单元操作的输入和输出设备
- 普林斯顿高等研究院 Princeton Institute for Advanced Studies – IAS
# 冯诺依曼结构的特点
- 计算机由五大部件组成
- 存储器,运算器,控制器,输入输出设备
- 指令和数据以同等地位位于读写存储器,可按地址寻访
- 指令和数据用二进制表示
- 指令由操作码和地址码组成
- 存储程序
- 以运算器为中心 (现在多以存储器为中心)
三个核心点:
- 数据和指令存储在一个读写存储器中
- 内存的内容是按位置寻址的
- 执行以顺序的方式进行
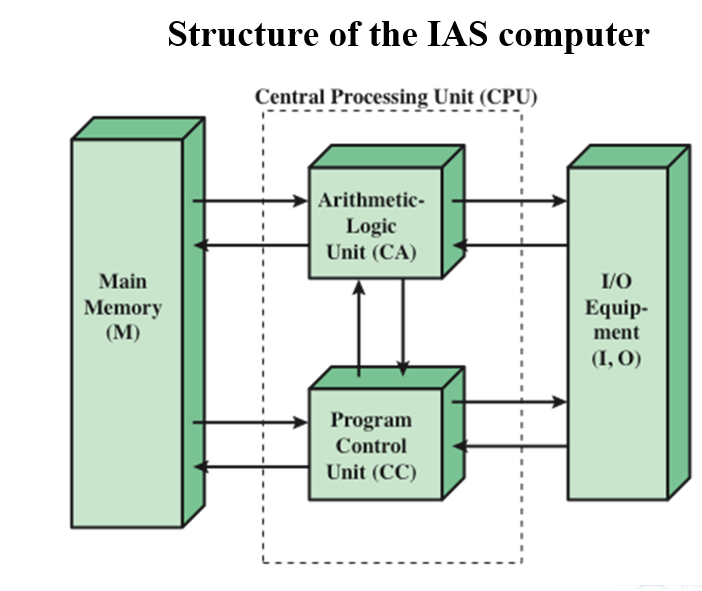
# IAS 计算机的结构
# IAS 内存格式
IAS 的内存由 1000 个存储位置 (称为字) 组成,每个位置 40 位
数据和指令都存储在那里
数字以二进制形式表示,每条指令都是一个二进制代码
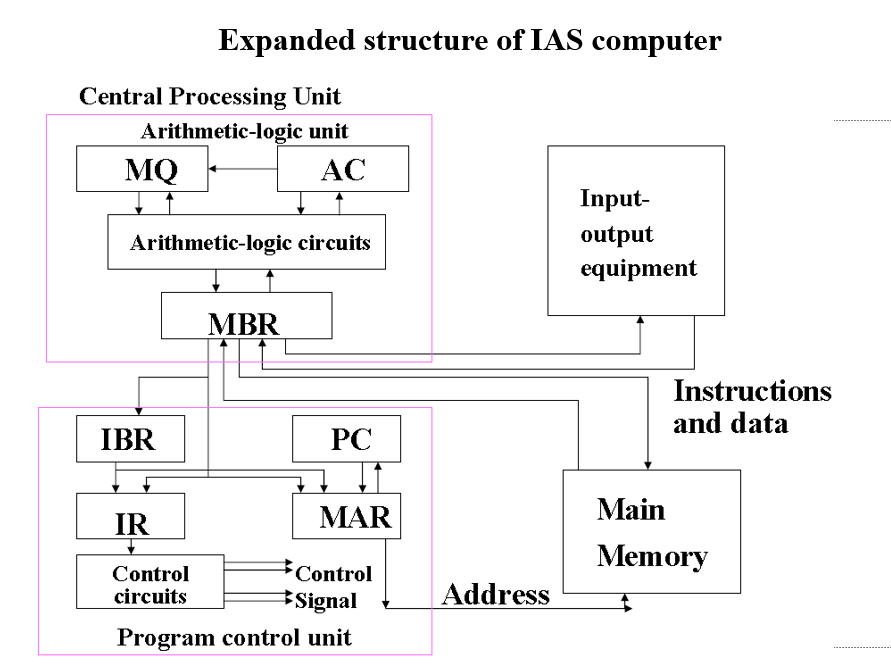
# IAS 寄存器
- 内存缓冲寄存器 Memory buffer register (MBR)
包含一个要存储在内存或发送到 I/O 单元的字
或用于从存储器或 I/O 单元接收一个字 - 内存地址寄存器 Memory address register (MAR)
指定要从 MBR 写入或读取的字在内存中的地址 - 指令寄存器 Instruction register (IR)
包含正在执行的 8 位操作码指令 - 指令缓冲寄存器 Instruction buffer register (IBR)
用来暂时记忆单词中的右手指令 - 程序计数器 Program counter (PC)
包含要从内存中获取的下一个指令对的地址 - 累加器和乘法器商 Accumulator (AC) and multiplier quotient (MQ)
用于临时保存 ALU 操作的操作数和结果
# IAS 结构的拓展
# IAS 指令集
- 21 个指令
- 数据传输
- 无条件转移
- 条件分支
- 算术
- 地址修改
# 摩尔定律
1965 年,戈登・摩尔 —— 英特尔的联合创始人
芯片上的晶体管数量每年都会翻一番
自 20 世纪 70 年代以来,发展有所放缓
晶体管的数量每 18 个月翻一番
芯片的成本几乎保持不变
更高的包装密度意味着更短的电路径,提供更高的性能
更小的尺寸增加了灵活性
降低电源和冷却要求
更少的互连提高了可靠性
# 微处理器
1971 年,英特尔开发 4004
第一个在单个芯片上包含 CPU 所有组件的芯片
微处理器的诞生
1972 年,英特尔开发了 8008
第一个 8 位微处理器
1974 年,英特尔开发 8080
第一种通用微处理器
更快,具有更丰富的指令集,具有较大的寻址能力
# 计算机计量单位

# 计算机性能设计
# 微处理器的速度
- CPU / 内存容量遵循摩尔定律
- 满足 CPU 速度的技术
分支预测
数据流分析
投机执行 - 其他关键组件的速度滞后于 CPU 的速度
CPU 必须等待
瓶颈
降低整体性能
特别是主存储器
解决办法:
- 优化系统结构,平衡 CPU、内存和 I/O 的整体性能
- 改进 CPU 和内存的接口
- 接口是负责传递指令和数据的关键路径
- 增加一次检索的位数
- 让 DRAM “更宽” 而不是 “更深”
- 更改 DRAM 接口
- 缓存
- 减少内存访问的频率
- 更复杂的缓存和片上缓存
- 增加互连带宽
- 高速总线
- 总线的层次结构
- 缓存和缓冲方案
- 更高速度的互连总线和更精细的互连结构
- 使用多处理器配置有助于满足 I/O 需求
# 芯片组织和架构的改进
- 提高处理器的硬件速度
- 主要是由于逻辑门尺寸的缩小
- 更多的门,更紧密地排列,增加时钟速率
- 减少了信号的传播时间
- 主要是由于逻辑门尺寸的缩小
- 增加缓存的大小和速度
- 处理器芯片专用部分
- 缓存访问时间显著降低
- 处理器芯片专用部分
- 改变处理器的组织和体系结构以提高指令执行的有效速度
- 并行性
# 时钟速度和登录密度的问题
- 功率
功率密度随逻辑密度和时钟速度的增加而增加
散热 - RC 延迟
电子流动的速度受到连接它们的金属线的电阻和电容的限制
延迟随着 RC 积的增加而增加
导线互连更细,增加电阻
导线靠近,增加电容 - 内存延迟
内存速度滞后于处理器速度
# Multicore, MICs and GPGPUs
# 多核
在同一芯片上使用多个处理器提供了在不增加时钟速率的情况下提高性能的潜力
策略是在芯片上使用两个更简单的处理器,而不是一个更复杂的处理器
对于两个处理器,更大的缓存是合理的
随着缓存变得越来越大,在芯片上创建两层,然后是三层缓存对性能有意义
# Many Integrated Core (MIC) 集成众核
性能上的飞跃,以及开发软件以利用如此大量的内核所面临的挑战
多核和 MIC 策略涉及单个芯片上通用处理器的同质集合
# GPU(Graphics Processing Unit )
- 设计用于对图形数据执行并行操作的核心
- 传统上在插件显卡上安装,它用于编码和渲染 2D 和 3D 图形以及处理视频
- 作为矢量处理器用于各种需要重复计算的应用程序
- 一个 GPU 可以支持广泛的应用 ——GPGPU
- 深度学习
# 嵌入式系统与 ARM
# 嵌入式系统
定义:计算机硬件和软件的组合,可能还有额外的机械或其他部件,设计用于执行特定功能
在许多情况下,嵌入式系统是一个更大的系统或产品的一部分,例如汽车的防抱死制动系统
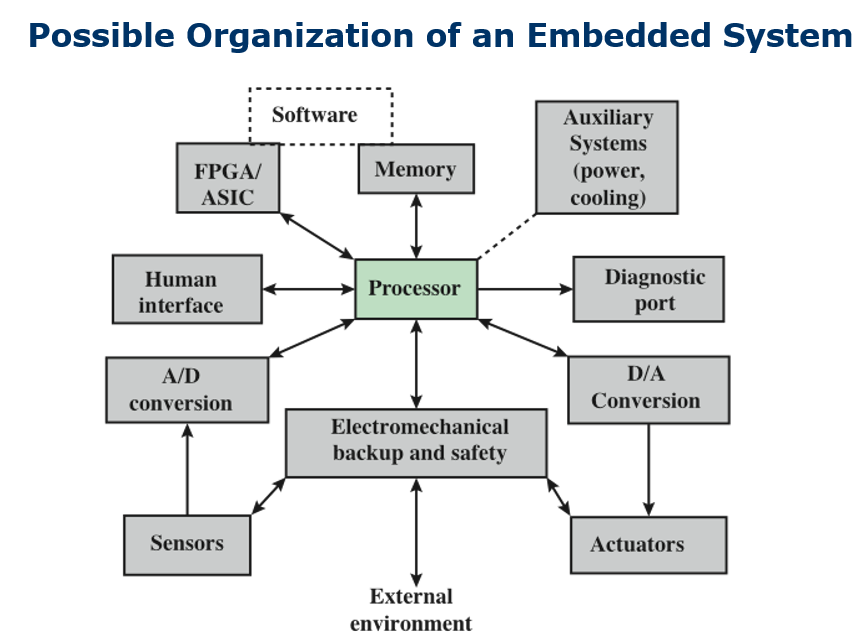
# Acorn RISC Machine (ARM)
基于 risc 的微处理器和微控制器家族
设计微处理器和多核架构,并将其授权给制造商
芯片是高速处理器,以其小芯片尺寸和低功耗要求而闻名
广泛应用于 pda 等手持设备
任何类型的最广泛使用的处理器架构
# 性能评估
# 时钟频率
处理器执行的操作由系统时钟控制
处理器的速度由系统时钟的脉冲频率决定,以每秒周期 (Hz)—— 时钟频率为单位
- 不精确的
# 处理器时间 T
- 处理器执行给定程序所需的时间
- T = 一个程序的 CPU 时钟周期 * 时钟周期 τ
= 程序的 CPU 时钟周期 / 时钟速率 - T= CPI ×IC × 时钟周期 τ = CPI ×IC / 时钟速率
- CPI: 每条指令的平均周期
- IC: 指令计数
- 受指令集体系结构、编译器技术、处理器实现和存储器层次结构的影响
# 处理器速度
- 指令执行的速度,以每秒百万指令表示 (MIPS)
- 即 MIPS 率
- 每秒数百万个浮点指令
-
- 用于科学和游戏应用
- 不充分的
# 基准套件
基准套件 Benchmark suite
- 用高级语言定义的一组程序
- 在某一特定应用或系统程序设计领域对计算机进行有代表性的测试
基准的理想特征 - 用高级语言编写,使它可以在不同的机器上移植
- 代表一种特定的编程风格
- 系统编程、数值编程或商业编程
- 测量容易
- 广泛的分布
# 标准性能评估公司
- SPEC (Standard Performance Evaluation Corporation)
行业联盟
定义并维护最著名的基准套件集合
性能测量被广泛用于比较和研究目的 - SPEC 规范 CPU2006
最著名的规格基准套件
用于处理器密集型应用程序而不是 I/O 的工业标准套件
由 17 个用 C、c 艹和 Fortran 编写的浮点程序和 12 个用 C 和 c 艹编写的整数程序组成
套件包含超过 300 万行代码
# Amdahl 定律
- 使用更快的执行模式所提高的性能受限于更快模式的执行时间占总执行时间的比例
- 提高的性能受到使用更快模式频率的限制
- 阿姆达尔定律定义了通过使用特定技术可以获得的速度
Speedup - 比率
- 使用增强的性能 / 不使用增强的性能
- 不使用增强的整个任务的执行时间 / 使用增强的整个任务的执行时间
![图2]()

# 例题
假设一个任务大量使用浮点运算,其中 40% 的时间被浮点运算消耗使用新的硬件设计,浮点模块的速度提高了 k 倍,这种增强获得的总体速度是多少?
# 词汇
-
Pipelining and parallel execution: 流水与并行执行
-
Speculative execution: 推测执行
-
Cache: 快速缓存
-
Decimal: 十进制
-
Binary: 二进制
-
General purpose computer: 通用计算机
-
Von Neumann Machine: 冯 - 诺依曼计算机
-
Opcode=operation code: 操作码
-
Instruction cycle: 指令周期
-
Fetch cycle: 取(读)周期
-
Flowchart: 流程图
-
Condition branch: 条件转移
-
Data transfer: 数据传送
-
Upward compatible: 向上兼容
-
Multiplexor: 复用器
-
Bus: 总线
-
Magnetic-core memory: 磁芯存储器
-
End user: 端用户
-
Speech recognition: 语音识别
-
Videoconferencing: 视频会议
-
Multimedia authoring: 多媒体编著
-
Workstation: 工作站
-
Client-server: 客户机 - 服务器
-
DRAM—dynamic random access memory: 动态随机存取存储器
-
Branch prediction: 转移预测
-
Throughput: 吞吐率
-
Trade-off : 折衷
-
Supercomputer: 超级计算机 / 巨型机
-
Parallelism: 并行性
# Key points
What is the first computer in the world?
What features of von Nuemann machine is there? How about its structure?
Moore law?
What is multicore, MICs and GPU?
CPI, Ic, T, MIPS, MFLOPS
Amdahl Law