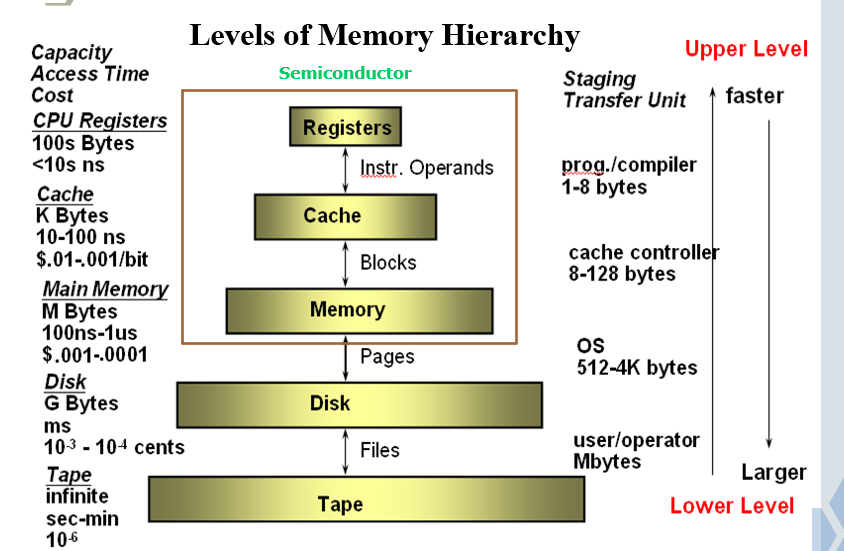
# overview
# Key characteristics of memory systems
-
Location: Internal, External, Offline
内存系统的关键特性。位置:内部外部离线 -
Capacity: word length, number of words- Unit of transfer: word, block
容量:字长,字数 - 传递单位:字,块 -
Access method: sequential, direct, random,associative
存取方法:顺序、直接、随机、联合 -
Performance: access time, access cycle,bandwidth
性能:接入时间、接入周期、带宽 -
Physical type: semiconductor, magnetic, optical,magneto-optical
物理类型:半导体、磁性、光学、磁光 -
Physical characteristics: volatile/nonvolatile,erasable/nonerasable
物理特性:易挥发 / 非易挥发、可擦除 / 不可擦除 -
Organisation: how to form bits to words
组织:如何形成字词
# 存储器的分层结构
- 对于存储器,我们关注的问题是:
- 容量
- 速度
- 价格
- 解决办法: 存储器分层组织
| 存储器的分层结构 |
|---|
| Cache |
| 主存 |
| 外存 (辅存) |
# 访问局部性
- 局部性原理:在程序执行过程中,处理器倾向于成簇(块)地访问存储器中的指令和数据
- 原因
- 程序通常包含许多循环和子程序 - 重复引用;
- 表和数组涉及对数据的成簇访问 - 重复引用
- 程序或数据都是按顺序存放,即将要访问的指令或数据通常在当前访问指令或数据附近
- 一般指令的局部性要强于数据的局部性
经验法则:
90/10 规律:所有代码中只有 10%被经常执行,并且其执行的时间差不多占整个程序执行时间的 90%
# 两种类型的局部性
- 时间局部性:如果正在访问一个数据或指令,那么在近期它很可能还会被再次访问
- 空间局部性: 即将要访问的数据或者指令很可能与现在正在访问的数据或者指令在地址上是临近的
# 高速缓存 Cache
- 根据局部性原理以及 90/10 规律,如果将经常访问的数据或代码存放在一个容量较小,但速度较快的存储器中可提升整个系统性能
- 在 CPU 和主存之间引入一级或多级高速缓存 Cache
# 两级存储器的性能
N_c: 第一级命中次数
N_{total}: 存储访问总次数
平均访问时间:
# Cache / 主存结构及其访问过程
# Cache 存储器原理
- 小而快的存储器
- 处在主存和 CPU 之间
- 可能位于 CPU 芯片或模块上
# Cache 是存储器分层结构的重要组成部分
- 相比主存,Cache 相对较小
- 能以接近处理器速度进行访问
- 与主存相相比每位价格较为昂贵
- Cache 存储的是主存部分内容的副本
# Cache / 主存储器结构
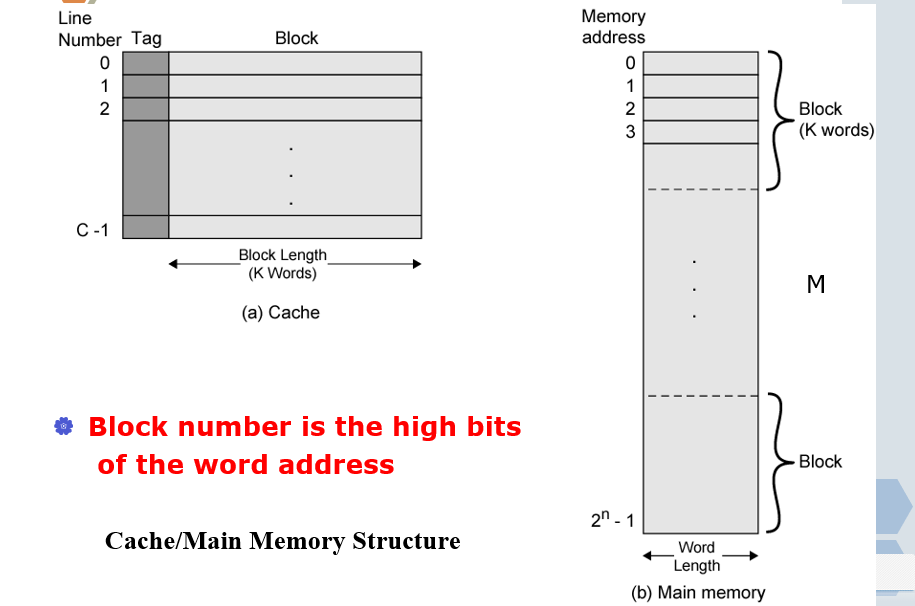
- 容量为 2n 个字的主存被划分成 M 个大小为 K 个字的块
- 总块数:M= 2^n /K
- Cache 也被划分成 C 个大小为 K 个字的行
- Cache 行大小 = 主存的块大小
- C<<M
- 任意时刻最多只能有 C 个主存块驻留在 Cache 中
- 多个主存块可以映射到同一个 Cache 行
- 每个 Cache 行不能被某块永久占用
- 每行都有一个标记域(Tag)来标识具体主存块
# 主存分块后的地址
块号是主存地址的高位,块内字号是主存地址的低位
| 主存地址 | 块号 | 块内字号 |
|---|---|---|
| 0000 | 000 | 0 |
| 0001 | 000 | 1 |
| 0010 | 001 | 0 |
| 0011 | 001 | 1 |
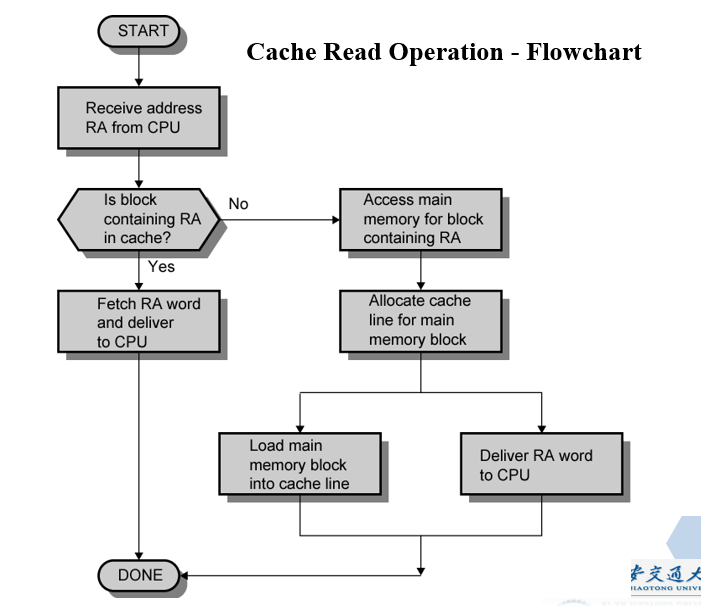
# Cache 的访问过程
- 主存储器的部分内容也在 Cache 中
- CPU 给出需要访问数据的主存地址
- 检查 Cache 是否包含此数据
- 如果命中,CPU 从 Cache 中获取该数据(快速)
- 如果未命中,将包含这个字的主存块装入 Cache
- 同时把这个块的 Tag 标记放入对应 Cache 行的标记域中
- 发送所需数据给 CPU
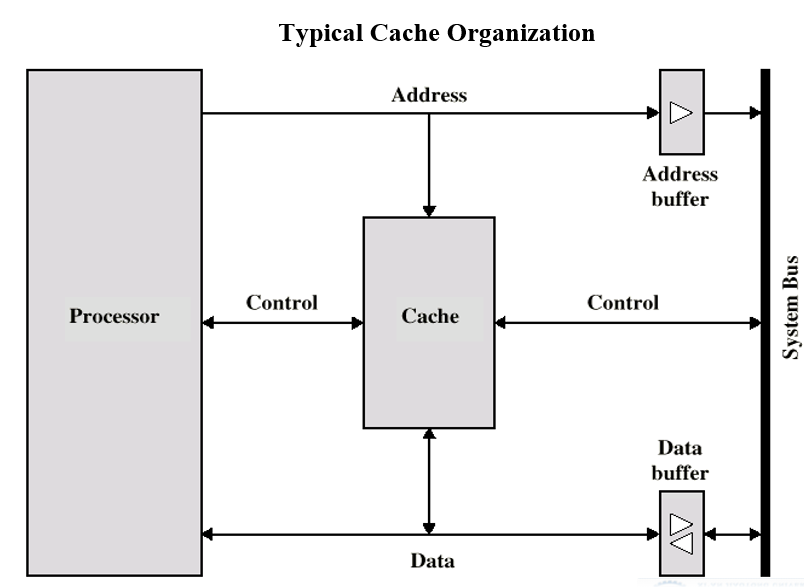
# 典型的 Cache 组织
# Cache 地址和容量
# Cache 地址
- 虚拟内存
- 允许程序在逻辑上访问更多地内存的地址,而不考虑实际可用的主存容量
- 当使用虚拟内存时,机器指令的地址字段包含的是虚拟地址
- 为了从主存中进行读写操作,需要一个硬件,即存储器管理单元(MMU)来将每个虚拟地址转换为主存的物理地址
- 使用虚拟地址时,根据 Cache 位置
# Cache 的容量
- 小容量 Cache
- 便宜,整个内存系统的平均价格基本接近于主存的价格
- 命中率较低,访问速度可能比直接访问主存还慢
- 大容量 Cache
- 命中率较高,接近 100%,访问速度可能接近 Cache 的访问速度
- 昂贵
- 门电路的数目更多,比容量小的 cache 稍慢
- 占用更多的 CPU 空间
- 需要在容量、价格和速度之间进行折中
- 没有最优值,1K〜512KB 都是可选的
# Cache 的映射机制
- Cache 的行数 C<< 主存的块数 M
- 需要一种机制来确定以下问题
- 某一主存块会映射到 Cache 的哪一行
- 当前是哪一个主存块正占据 Cache 的某一行
- 映射机制采用硬件实现
- 映射机制决定 Cache 的结构
- 典型的映射机制:
- 直接映射
- 全关联映射
- 组关联映射
# 直接映射
- 最简单的一种映射技术
- 主存块 -> Cache 固定的行:
i = j mod m
其中: i = Cache 的行号
j = 主存的块号
m =2^r =Cache 的总行数 - 块号对行数 m 取余后余数相同的主存块会被映射到同一个 Cache 行
- 块号低 r 位相同的块都会被映射到对应的那一个 Cache 行中
# 直接映射的实现
- 最低的 w 位标识某行的具体一个字或字节
- 中间的 r 位标识 Cache 中具体的某一行
- 剩下最左边的若干位标记(Tag)来识别这个数据究竟是不是 CPU 所需要的那个数
- Tag 用来确定主存的某一个具体的块
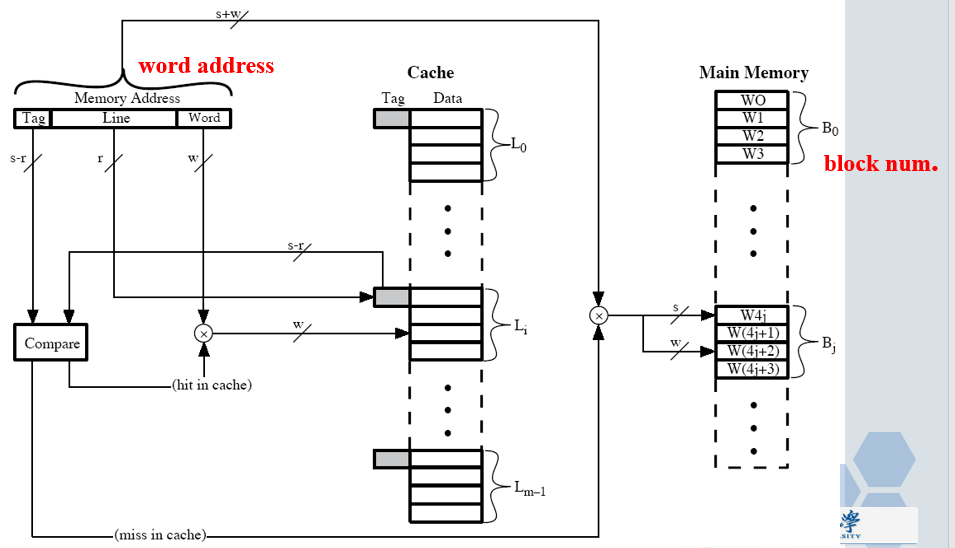
- 24 位地址
- 字号域 = 2 ->1 个主存块或 Cache 行包含 22=4 个字或字节
- 行号域 = 14->Cache 的行数 m=2r=2=16K
- Tag 域 = 8 ->28 个不同块可以放到同一 Cache 行
- 没有两个对应同一 Cache 行的块会具有相同的标记 tag 域
- 在 Cache 中进行查找的时候是依据地址中提供的行号以及标记进行的

# 直接映射的优缺点
- 简单
- 实现起来成本低
- 给定的某一块映射到 Cache 行的位置是固定的
- 如果一个程序恰巧需要重复访问两个被映射到同一行的不同块的数据,此时 Cache 的命中率会很低
- –抖动现象
# 全关联映射
主存的任意一个块可以对应到 Cache 的任意一行
主存的块和 Cache 的行没有固定的映射关系
# 全相联映射的实现
- Cache 控制器将主存地址切分为两部分
- 剩下左边的若干位标记(Tag)用来唯一标识一个主存块
- 数据块的标记 Tag 必须同数据块一起被存储到 Cache 每一行 Tag 域中:
- 每个 Cache 行的 Tag 域较长
- Tag 即为块号
- 24 位地址
- w=2->1 个主存块或 Cache 行包含 22=4 个字或字节
- 前面的 22 位标记唯一的指定该地址所对应的主存块
- 不同块的 Tag 域一定不同
# 全相联映射地址结构
- 在 Cache 中进行查找时,必须比较 Cache 中所有行的标记域 tag 以确定是否命中
- 并行的比较
- 比较复杂且昂贵
![6]()
![7]()
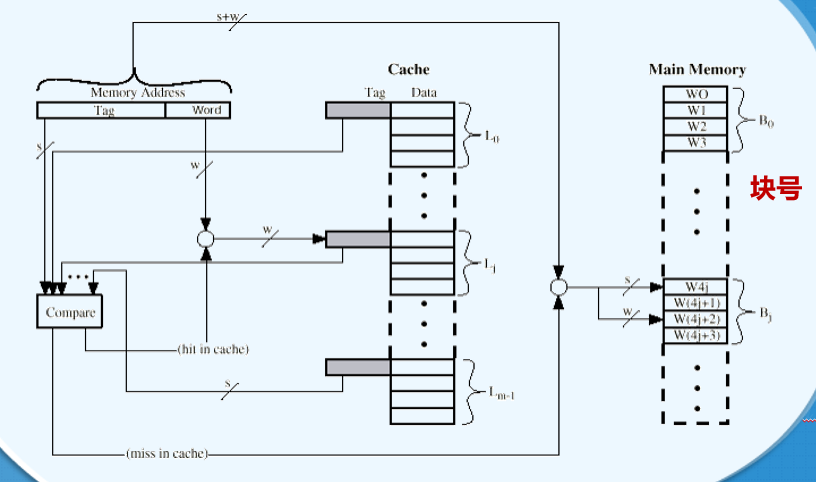

# 全相连映射的优缺点
- 优点:
- 主存块可以映射到 Cache 的任意一行
- 装入和替换灵活
- 缺点:
- 需要并行比较电路
- 复杂且昂贵
- 系统开销大
- 只适合于一些容量较小、功能特殊的 Cache
# 组关联映射
- 把 Cache 的行再分成组,每一组包含有相同数目的连续的行,主存块和 Cache 组之间进行直接映射,而在组内块和行之间采用全关联映射的机制
- 组关联映射 = 直接映射 + 全关联映射
- m 行的 Cache 被分为 v 组,每组包含 k 行,被称为 k 路组关联
- k 路组关联映射下具有关系:
- 总行数 m = 总组数 v * 组内行数 k
- k=1,直接映射
- v=1,全关联映射
- 主存块 j 和其对应的 Cache 组号 i
组号 i = 块号 j mod Cache 的总组数 v - Cache 的总组数 v = 2^d
- 命中率和组内行数 k 没有必然联系
- k 取 2~8 都是可以的
- 总行数 m = 总组数 v * 组内行数 k
- 给定的主存块可以映射到 Cache 固定某组的任意一行
- 块号低 d 位相同的块都会被映射到对应的那一个 Cache 组中
- 常用两路的组关联结构,相比直接映射它明显提高了 Cache 命中率
# 组关联映射的实现
- Cache 控制器将主存地址分为三部分
- 最低的 w 位标识某行的具体一个字或字节
- 中间的 d 位标识 Cache 中某一具体组
- 剩下最左边的若干位标记(Tag)来确定这个数据究竟是不是 CPU 所需要的那个数
- Tag 用来确定主存的某一个具体的块
# 组关联映射地址结构
- 24 位地址
- 字号域 = 2->1 个主存块或 Cache 行包含 2^2=4 个字或字节
- 组号域 = 13->Cache 的组数 v=2d=2=8K
- Tag 域 = 9 ->2^9 个不同块可以放到同一 Cache 组
- 对于一个组内的不同块,标记 Tag 是唯一的
- 同一组内不会有 Tag 位相同的行
- 不同组内可以有 Tag 位相同的行
- 在 Cache 中进行查找的时候是依据地址中提供的组号以及标记进行的
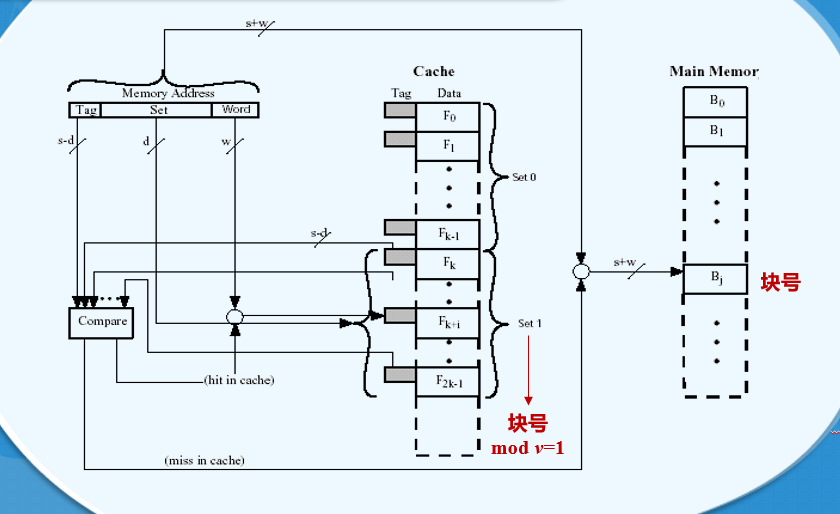

# 三种映射机制比较

# Cache 的替换算法
# 替换算法 1 直接映射
- 没有选择
- 每个主存块只能映射到固定一行
- 替换时直接替换对应 Cache 的那一行数据
# 替换算法 2 全相联映射 / 组相联映射
- 硬件实现
- 先进先出算法 (FIFO)
- 替换掉在 Cache 中驻留时间最长的块
- 最不经常使用算法(LFU)
- 替换掉 Cache 中被访问次数最少的块
- 最近最少使用算法 (LRU)
- 替换掉那些在 Cache 中驻留时间最长且最近未被访问过的块
- 随机算法 (Random)
- 随机从候选行中选取一个进行替换
- 最优替换算法 (Optimized)
- 替换时就替换掉那个将来使用最少的行
- 评价标准
# 单机情况下 Cache 的写策略
- 与读取不同,Cache 的写入更为复杂
- 需要保证 Cache 和主存之间数据的一致性
- 单 CPU 系统的两种 Cache 写策略
- 写直达(Write through)
- 写回法 (Write back)
# 写直达
- 思想:写 Cache 的同时写主存
- 所有写操作都同时对主存和 Cache 进行
- 优点:保证 Cache 数据和主存数据的严格一致
- 缺点:产生了大量写的信息流,可能引起瓶颈问题,降低写入速度
- 不适合迭代运算较多的场合
# 写回法
- 思想: CPU 写 Cache 数据后不立即写回主存,而只是置位被修改行的标记,当发生替换时,当且仅当标记位被置位的时候,才将它回写到主存。
- 初始的写只更新 Cache 中的数据
- 写数据的同时对应行的标记位被置位
- 当某一 Cache 行需要被替换掉时,当且仅当标记被置位时才将它写回主存,再进行替换。
- 如果标记位没有置位,替换时直接覆盖该行即可。
- 优点:写的速度比较快,避免了中间无用数据的写回
- 缺点:某段时间部分主存数据是无效的,电路复杂
- 适合于那种 IO 模块直接和 Cache 进行连接的系统
# Cache 行大小和 Cache 数目
# Cache 行大小与命中率
- 依据局部性原理
- 被访问字附近的数据很可能在不久的将来被访问到
- 在某种程度上,增加行大小会使得命中率增加
- 当块的大小相对于 Cache 总容量过大时,命中率开始下降
- 较大的行会减小 Cache 的总行数,替换的代价会变大。●使用新数据的概率小于被替换数据的概率。
- 块大小与命中率之间的关系复杂,它取决于特定程序的局部性特征
没有找到确定的最优值
块大小为 8~64B 比较合适
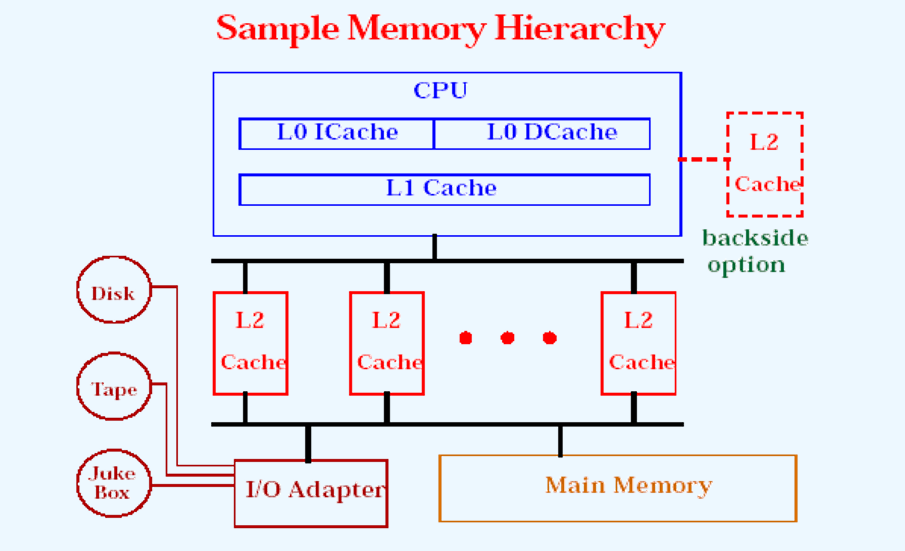
# Caches 的数目
# 单一 Cache 和多级 Cache
- 片内 Cache (L1) : 到 CPU 的路径短,速度快,减少了对总线访问。
- 外部 Cache (L2)∶只有 Ll 访问未命中会导致访问 L2。
- 多级 Cache 能显著地提高性能,
- 但多级 Cache 也会使关于 Cache 设计的所有问题变得复杂
# 统一 Cache 和分立 Cache
- 统一 Cache
- 一个 Cache 既能装入指令又能装入数据
- 在获取指令和数据之间能自动加以平衡
- 命中率高
- 分立 Cache
- 存放单一信息的
- 专用 Cache 数据 Cache & 指令 Cache、TLB
- 并行性好
- 更好的支持指令的并行
- 结合使用
# 词汇
-
DRAM(Dynamic random-access memory): 动态随机存取(访问)存储器
-
ZIP Cartridge: ZIP 活动磁盘
-
Controller:控制器
-
Capacity: 容量
-
Unit of transfer:传送单元
-
Addressable unit:可寻址单元
-
Sequential access:顺序访问
-
Associative access: 关联访问
-
Nonvolatile memory: 恒态存储器
-
WORM(write once read many): 一写多读存储器
-
MO(magneto-optical disk): 磁光盘
-
Set associative mapping:组关联映射
-
Replacement Algorithm: 替换算法
-
FIFO(first-in- first- out):先进先出
-
LRU(least frequently used):最近最少使用
-
Write through:写直达
-
Retire unit:回收单元
-
Consistency:一致性
-
Coherency:一致性
# key points
How about Memory Hierarchy? What executes it according to?
Where can block be placed in cache?
How is block found in cache?
Which block is replaced on miss in cache?
How about writes policy in cache?